Bogatsze dane w SpeechZap: paragrafy, slug i tagi
To jest wpis z serii 1 sukces dziennie.
W tej serii publikuję codziennie jeden sukces, który osiągnąłem poprzedniego dnia. To praktyczna implementacja podejścia z książki Show Your Work!
Codziennie zapisuję swoje postępy w SlowTracker – aplikacji do zapisywania sukcesów. Następnego dnia rano wybieram jeden lub kilka i tworzę z nich krótki post.
W wersji subskrypcyjnej dyktafonu SpeechZap do tej pory, na wzór Chat GPT, tworzyłem automatycznie tytuł na podstawie treści transkrypcji. Dzięki temu łatwiej jest odnaleźć nagranie na liście lub przypomnieć sobie o czym było.
Ale AssemblyAI daje też, zupełnie bezpłatnie (choć nie out-of-the-box), możliwość podzielenia całej transkrypcji na zdania lub paragrafy. O ile dzielenie na zdania nie jest mi potrzebne, o tyle paragrafy pomagają w redakcji dłuższych treści.
Zmieniłem więc teraz sposób wyświetlania treści:

Funkcja klikania w konkretne słowa, aby przejść do odpowiadającego mu fragmentu nagrania również jest dostępna.
Ponadto podczas generowania tytułu, tworzę również listę tagów, które dołączam do całej struktury danych. W przyszłości będę je być może pokazywał na liście, aby ułatwić zarządzanie notatkami, ale nie mam jeszcze pomysłu gdzie i jak to zrobić, żeby nie zaciemnić obrazu. (Może masz pomysł? Napisz na support@speechzap.com!)
Dla przykładowego nagrania…
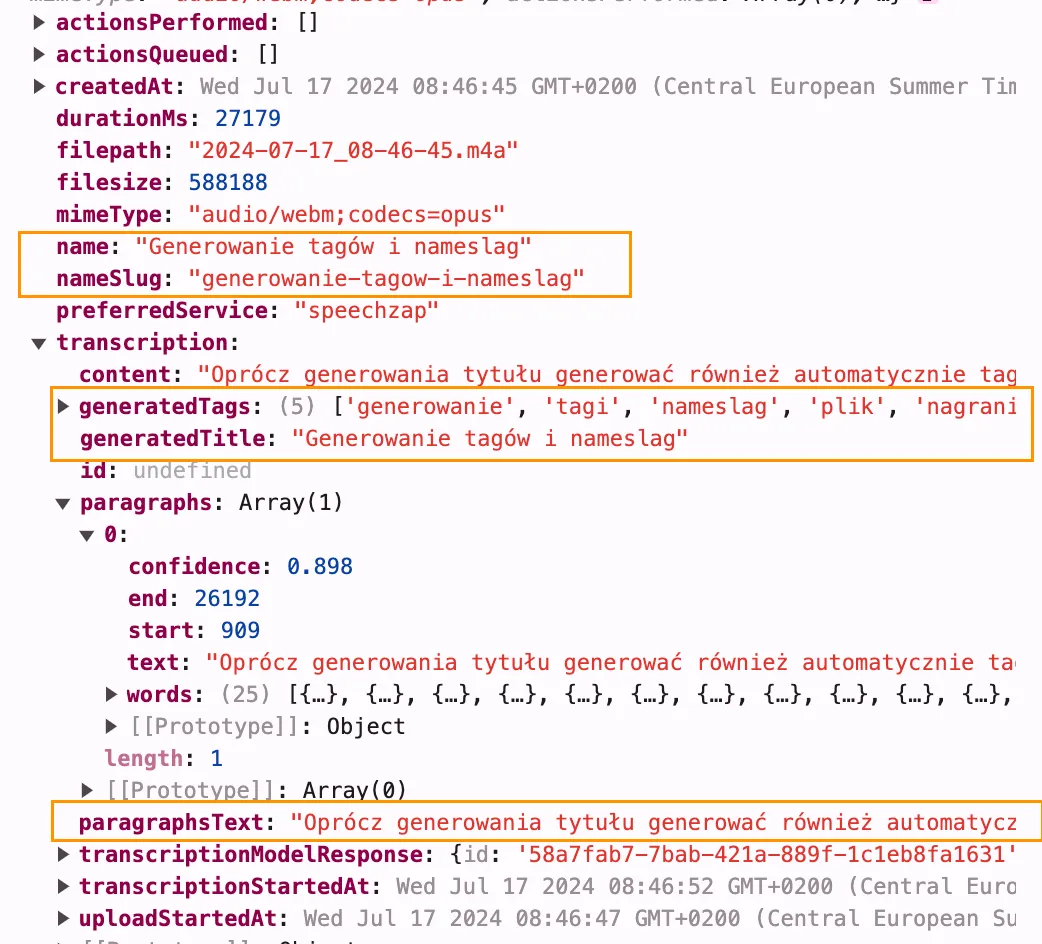
… struktura danych, w której znajdziesz:
name- pełna nazwa nagrania, którą możesz edytować w aplikacjinameSlug- nazwa bez znaków specjalnych, przydaje się do tworzenia nazwy pliku, np. w ObsidiangeneratedTags- lista tagów wygenerowana przez SpeechZapgeneratedTitle- nazwa wygenerowana przez SpeechZapparagraphs- pełna lista paragrafów z dodatkowymi informacjami z AssemblyAIparagraphsText- pełny tekst paragrafów, każdy oddzielony podwójnym znakiem nowej linii (\n\n)
… będzie wyglądać tak:
Cała ta struktura wysyłana jest po kliknięciu w dodaną akcję ↗. O integracjach dowiesz się więcej na moim kanale YouTube ↗.